 AirScript文档
AirScript文档主题
Python✖️表格
提示
目前PY脚本编辑器功能处于邀请内测阶段,后续会逐步推广到所有使用智能表格产品的用户 如何开通该功能/看不到该功能入口,可戳👉传送门
开始使用 Python
在金山文档的智能表格产品中使用 Python,请在文档顶部信息区选择效率 > PY脚本编辑器

打开PY脚本编辑器功能的侧边栏后,可以看到文档内已经存在的Python文件和模板 点击新建,创建Python文件,进入Python编辑栏,进行代码编辑 开始之前,也可以点击从模板开始,参考示例入门,了解表格中Python的使用
如何开通该功能/看不到该功能入口
- 因该功能目前处于邀请内测阶段,暂未对所有用户开放
- 如需使用,可申请加入Python X 表格内测体验,点击填写金山表单即参与报名,工作日18:00前提交,当天晚上将开通,超过18:00提交,请耐心等待下一个工作日晚上开通
- 该功能目前仅支持金山文档kdocs.cn在线智能文档中的【智能表格】,暂不支持Office文档
| 更新日志(每周五持续更新ing) | |
|---|---|
| 12.15更新 | • 优化了输出图表插入和刷新的速度,使用更加丝滑 • 优化了输出图表的初始化动画 • 优化了输出图表的尺寸自适应 • 模板库新增了使用pyecharts创建可视化展示数据频率的词云图模板 • 修复了一些已知的问题 |
| 12.08更新 | • py脚本发送出去的网络请求,使用固定出口 IP 地址 • xl() 函数和write_xl()函数,新增了 start_row,start_column参数(从0开始),方便控制访问位置• write_xl() 函数新增了book_url 参数,可以用来向其他表格写入数据 • dbt()函数采用自定义的dtype 返回附件类型数据,可以通过自定的Series Acces获取附件的临时下载地址,例如 df =dbt();df["图片和附件"].attachments.temporary_url()(目前附件的Dtype还未定义操作符,对附件列的操作可能会失败,后续会继续完善)• 新增了 echarts() 函数,方便大家体验echarts绘图,例如:echarts({echarts_options}).render(),详见echarts()函数,也可以在模板库中查看使用pyecharts的模板示例 |
| 12.01更新 | • 入口更名为PY脚本编辑器,升级了界面,丰富了模板库,欢迎体验• 编辑器新增了自动换行和深色模式,提升Python编程效率&体验• 应广大用户所需,新增了使用 Python发送网络请求的能力,可在 编辑器-服务列表-网络API开关中启用该功能• 第三方库新增了 akshare, tushare, baostock,详见第三方依赖 |
| 11.24更新 | • 支持了echarts库,提供了直观、生动、可交互、可个性化定制的数据可视化图表。更多关于echarts的用法请参考官方教程• 原插入图片优化为了插入 webshape对象• xl()函数支持同时获取多个 sheet的数据,通过设置 sheet_name=['foo','bar'],或直接使用 sheet_name=None 获取所有工作表的数据• 新增 dbt()函数获取数据表中的记录;新增insert_dbt()函数,向数据表中添加记录;新增update_dbt()函数,更新数据表中的记录 |
| 11.17更新 | • 输出结果插入表格后,可以通过点击刷新将结果更新至最新状态,也可以通过点击编辑来修改对应的py脚本代码 • 打开已有py脚本时,自动显示最近一次运行的输出结果 • 表格中暂停继续开放入口,建议移步至智能表格中体验使用 • 修复了一些已知的问题 |
| 11.10更新 | • 支持了回写数据到表格,可以通过内置的write_xl() 函数,将数据写入到表格• 修复了一些已知问题 |
| 11.03更新 | • Python内测Beta版发布,内置了多个Python第三方依赖,包括 pandas、matplotlib、numpy、pytorch等,可直接在代码中 import 这些依赖并使用,详见第三方依赖 |
使用Python访问表格里的数据
注意
金山文档的表格类产品中有工作表和数据表的区别,不同的表格类型,读取/写入数据要使用的函数是不同的。
访问工作表数据
在工作表中,可以使用区域选择器,选择要访问的数据范围。在编辑代码的过程中,可以随时通过点击编辑栏上方的选择器图标,唤出区域选择器。
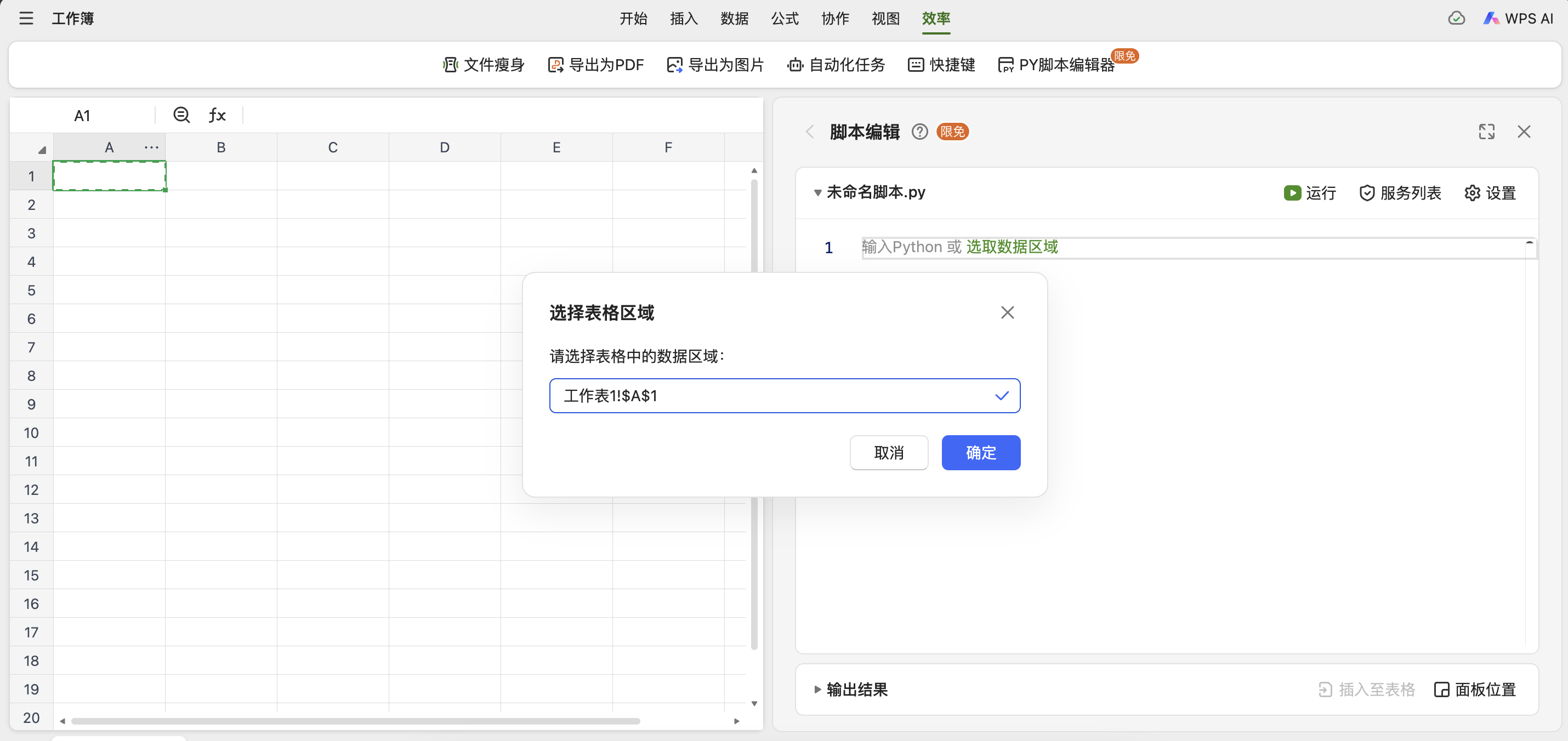
也可以直接使用内置的xl()函数,来访问工作表里的数据。例如:若要访问当前工作表的A1到G10单元格,可以使用xl("A1:G10")。xl()函数将返回一个包含选区内数据的pandas.DataFrame对象。
更多关于xl()函数的用法,请参考附录xl()函数部分的介绍。
访问数据表数据
可以使用内置的dbt()函数,来访问数据表里的数据。例如:若要访问当前数据表的全部数据,可以使用dbt()。dbt()函数会返回一个包含数据表内全部记录的pandas.DataFrame对象。
更多关于dbt()函数的用法,请参考附录dbt()函数部分的介绍。
输出
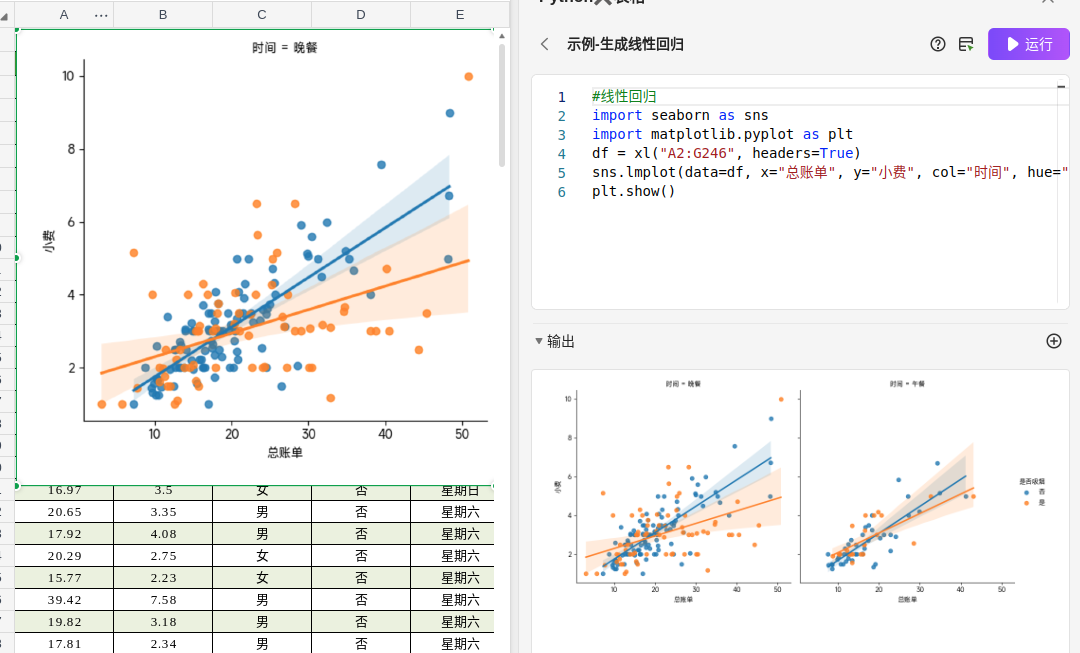
完成代码编辑后,点击编辑栏顶部的运行按钮,运行代码。运行的结果会显示在编辑栏底部的输出栏。输出的内容包括运行过程中通过print()等函数打印的中间结果以及可能出现的运行时错误。
点击输出栏右侧的加号图标,可以将输出的结果插入到表格中。
回写数据到工作表
可以通过内置的write_xl()函数,将数据回写到工作表。例如,将一个 pandas.DataFrame 类型的对象 df 回写到当前工作表的 A1 位置,可以使用write_xl(df, "A1"),它将在 A1 单元格所在的位置,逐行写入df中的数据。
更多关于write_xl()函数的用法,请参考附录write_xl()函数部分的介绍。
回写数据到数据表
数据表组织数据的方式与传统的工作表不同,因此回写数据的方式也有区别:
注意
对数据表的回写,目前函数提供的支持是不完备的。请根据需要酌情使用。
由于数据表中的某些字段类型是对象,这些字段的值在回写时,会被忽略或修改成简单类型。请参考附录数据表字段类型部分的介绍。
1. 添加记录
可以使用insert_dbt()函数,向数据表中添加记录。例如,将一条姓名为张三,年龄为20的记录添加到数据表,可以使用insert_dbt({"姓名": "张三", "年龄": 20}),它将在当前数据表的末尾添加一条新的记录。
更多关于insert_dbt()函数的用法,请参考附录insert_dbt()函数部分的介绍。
2. 更新记录
可以使用update_dbt()函数,更新数据表中的记录。例如,更新一条ID为D的记录,可以使用update_dbt({"_rid": "D", "年龄": 25})。
更多关于update_dbt()函数的用法,请参考附录update_dbt()函数部分的介绍。
第三方依赖
目前表格中已经内置了多个 Python 第三方依赖,包括 pandas、matplotlib、numpy、pytorch等。可以直接在代码中 import 这些依赖并使用。
完整的第三方依赖请参考附录内置的第三方依赖部分的介绍。
提示
目前暂时不支持安装和使用未内置的第三方依赖。
附录
xl() 函数
访问工作表中的数据,并返回一个pandas.DataFrame对象。
函数签名
python
def xl(range: str = "",
headers: bool = False,
sheet_name: str | list[str] = "",
book_url: str = '',
start_row: int | None = None,
start_column: int| None = None) -> pandas.DataFrame | dict[str, pandas.DataFrame]: ...参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| range | str | 空字符串 | 工作表中的选区描述。 默认为工作表中已经使用的区域。 |
| headers | bool | False | 是否将当前选区第一行处理为表头。 |
| sheet_name | str or list | 空字符串 | 选区所在的工作表名称,可为多个。 默认为当前激活的工作表。 如果为 None则返回全部工作表数据。 |
| book_url | str | 空字符串 | 选区所在的表格文件地址。 必须为金山文档云文档地址。 默认当前表格。 |
| start_row | int | None | 选区左上单元格的行,从0开始 |
| start_column | int | None | 选区左上单元格的列,从0开始 |
示例
以下示例会使用到如下虚拟的进销存表格,并假设当前正在打开的是工作表1(激活状态)。
提示
表格中的数据均虚构,仅做示例使用。
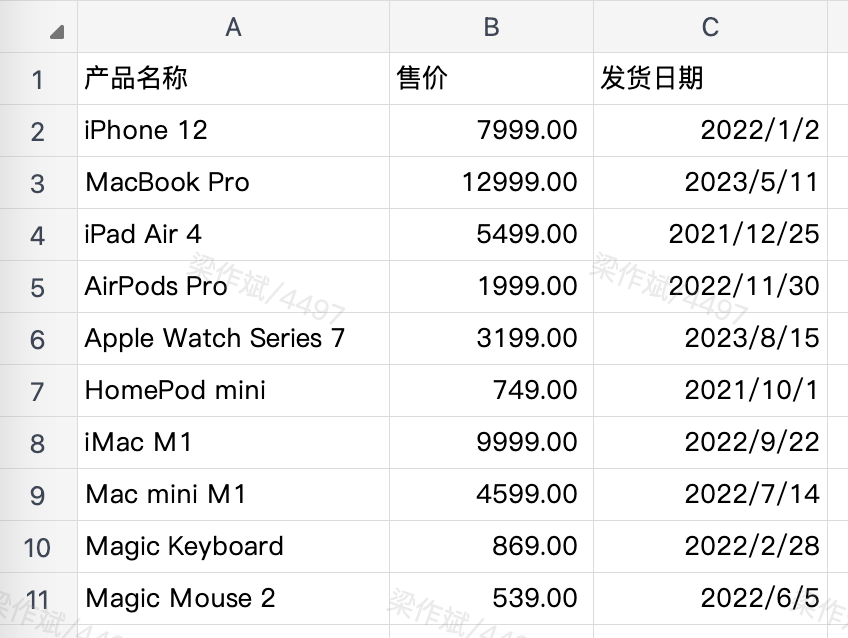
- 访问当前工作表(
工作表1)中的所有数据,无表头。
python
# 相当于 df = pandas.DataFrame(columns=None, data={全部数据})
df1 = xl()
# 由于无表头,只能按照索引访问 df 中的数据
# 下边这条语句会输出“产品名称”
print(df1[0][0])- 访问当前工作表(
工作表1)中,A1:C5区域的数据,将第一行处理为表头。
python
# 相当于 df = pandas.DataFrame(columns=[A1:C1], data=[A2:C5])
df2 = xl("A1:C5", headers=True)
# 可以通过列名来索引 df 中的数据
df2_subset = df[['产品名称', '发货日期']]- 获取
工作表2(当前激活为工作表1)中,A1:G10区域的数据,将第一行处理为表头。
python
# 相当于 df = pandas.DataFrame(columns=[A1:G1], data=[A2:G10])
df3 = xl("A1:G10", headers=True, sheet_name="工作表2")- 获取其它表格文档(
https://kdocs.cn/l/foo)中,工作表3的前10行数据,第一行作为表头。
python
df4 = xl(
range="1:10",
headers=True,
sheet_name="工作表3",
book_url="https://kdocs.cn/l/foo",
)- 获取当前表格中,所有工作表数据。
python
# 此时将返回一个 dict[str, pandas.DataFrame] 类型的 ds
# ds 的 key 为工作表名称
ds = xl(
headers=True,
sheet_name=None,
)
df5 = ds['工作表1']write_xl() 函数
将数据回写到工作表。
注意
支持将一维和二维的容器对象,如 list tuple set dict 回写到工作表,不支持更高维度的容器的回写。
提示
一维容器对象:向量表示,容器中不包含其它容器;
二维容器对象:矩阵,容器中的元素为只包含标量的容器。
提示
不同类型的数据回写时处理逻辑是不同的。请参考示例部分获取更多信息。
函数签名
python
def write_xl(data: object,
range: str = "",
new_sheet: bool = False,
sheet_name: str = "",
overfill: bool = True,
book_url: str = "",
start_row: int | None = None,
start_column: int| None = None) -> None;参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| data | object | 必填 | 要回写到工作表里的数据。 支持的数据类型包括: Python 基本数据类型; 维度不超过2维的容器类型,如: list 和 tuple;pandas.DataFrame;不支持写入图片。 |
| range | str | 空字符串 | 工作表中的选区描述。 可以为一个单元格。为要写入数据的选区的左上角。 当 new_sheet=True时可以为空。默认为新工作表的A1位置。 |
| new_sheet | bool | False | 是否将数据写入到新建的工作表中。 |
| sheet_name | str | 空字符串 | 写入数据的选区所在的工作表名称。 当 new_sheet=False 时为表格中已经存在的工作表名称。当 new_sheet=True 时为新建的工作表的名称。 |
| overfill | bool | True | 当 range 不足以容纳 data 时,是否允许超出部分继续写入。如果设置为 False 超出 range 的 data 部分会被丢弃。 |
| book_url | str | 空字符串 | 选区所在的表格文件地址。 必须为金山文档云文档地址。 默认当前表格。 |
| start_row | int | None | 选区左上单元格的行,从0开始 |
| start_column | int | None | 选区左上单元格的列,从0开始 |
示例
- 将字符串、数字回写到工作表。
python
# 将 s 回写到当前工作表的 A1 单元格
s = "hello world"
write_xl(s, "A1")
# 将 i 回写到工作表2的 B1 单元格
i = 100
write_xl(i, "B1", sheet_name="工作表2")
# 将 f 回写到新建的工作表中的 C1 单元格
f = 0.1
write_xl(f, "C1", new_sheet = True)- 将
pandas.DataFrame回写到工作表。
提示
将 DataFrame 回写到工作表时,是按照数据在 DataFrame 中的相对位置(行/列)进行写入的。如果设置了 overfill=False 超过选区 range 的部分会被丢弃。
python
import pandas as pd
# 构造一个有 columns 的 DataFrame
df = pd.DataFrame({"Name": ["foo", "bar", "baz"], "Age": [1, 2, 3]})
# 将 df 写入到当前工作表的 A1 位置
# 由于 df 中包含 columns 定义
# 最终会写入到 A1:B4 选区
# 相当于第1行是表头,其余3行为数据
# +-------+-----+
# | Name | Age |
# +-------+-----+
# | foo | 1 |
# +-------+-----+
# | bar | 2 |
# +-------+-----+
# | baz | 3 |
# +-------+-----+
write_xl(df, "A1")
# 构造一个无 columns 的 DataFrame
df2 = pd.DataFrame([["foo", 1], ["bar", 2], ["baz", 3]])
# 将 df2 写入到当前工作表的 A1 位置
# 由于 df2 中没有 columns(未显式定义,默认使用 pandas.RangeIndex)
# 最终会写入到 A1:B3 选区
# 相当于没有表头,只有3行数据
# +-------+-----+
# | foo | 1 |
# +-------+-----+
# | bar | 2 |
# +-------+-----+
# | baz | 3 |
# +-------+-----+
write_xl(df2, "A1")
# 也可以单独回写某个 series,行为与只有一个“列”的 DataFrame 一致
write_xl(df['name'], "A1:B1")- 将
list、tuple和set回写到工作表。
提示
示例中仅包含 list。set和tuple的逻辑与list一致。
- 将一维
list、tuple和set回写到工作表。
注意
当 range 是一个矩阵(例如:“A1:C10”),如果list或tuple或set中包含的数据长度(len()函数返回的长度)大于range选区的大小,且overfill=True会返回错误并写入失败。因为此时无法推断出要向工作表的哪个方向(行/列)去做扩张。
python
# 构造一个有10个元素的 list
l = [i for i in range(10)]
# 将 l 回写到以 A1 开头的一行中
# +-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
# | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
# +-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
write_xl(l, "A1")
# 将 l 回写到当前工作表的 A1:C1 区域
# 即将 l 回写成工作表中的一行
# 但是此时 A1:C1 选区不足以容纳 10 个元素
# 且 overfill=False 截断 l 中的元素
# +-----+-----+-----+
# | 0 | 1 | 2 |
# +-----+-----+-----+
write_xl(l, "A1:C1", overfill=False)
# 将 l 回写到当前工作表的 A1:A10 区域
# 与之前的示例相同,即将 l 回写成工作表中的一列
# +-----+
# | 0 |
# +-----+
# | 1 |
# +-----+
# | 2 |
# +-----+
# | 3 |
# +-----+
# | 4 |
# +-----+
# | 5 |
# +-----+
# | 6 |
# +-----+
# | 7 |
# +-----+
# | 8 |
# +-----+
# | 9 |
# +-----+
write_xl(l, "A1:A10")
# 将 l 回写到当前工作表的 A1:E2 区域
# 即将 l 回写成工作表中2行*5列
# 此时要求 l 的长度必须不大于选区的长度
# 否则无法判断该如何写入数据,导致报错
# +-----+-----+-----+-----+-----+
# | 0 | 1 | 2 | 3 | 4 |
# +-----+-----+-----+-----+-----+
# | 5 | 6 | 7 | 8 | 9 |
# +-----+-----+-----+-----+-----+
write_xl(l, "A1:E2")- 将二维
list、tuple和set回写到工作表。
注意
容器中的元素会被处理成工作表的一个行。
python
# 构造一个二维的 list
data = [["foo", 1], ["bar", 2], ["baz", 3]]
# 将 data 回写到当前工作表的 A1 位置
# 将会在工作表中写入如下数据:
# data 中的每一个子列表,被处理成工作表中的一行
# +-------+-----+
# | foo | 1 |
# +-------+-----+
# | bar | 2 |
# +-------+-----+
# | baz | 3 |
# +-------+-----+
write_xl(data, "A1")- 将
dict回写到工作表。
注意
dict的key被当作表头中的列名;value被处理成一列数据。
python
# 构造一个一维的 dict
data = {"Name": "foo", "Age": 1}
# 将 data 回写到当前工作表的 A1 位置
# 将会在表个中写入如下数据:
# +-------+-----+
# | Name | Age |
# +-------+-----+
# | foo | 1 |
# +-------+-----+
write_xl(data, "A1")
# 构造一个二维的 dict
data = {'Name': ['foo', 'bar', 'baz'], 'Age': [1, 2, 3]}
# 将 data 回写到当前工作表的 A1 位置
# 将会在工作表中写入如下数据:
# +-------+-----+
# | Name | Age |
# +-------+-----+
# | foo | 1 |
# +-------+-----+
# | bar | 2 |
# +-------+-----+
# | baz | 3 |
# +-------+-----+
write_xl(data, "A1")数据表中的字段类型
| 字段类型 | 类型名称 | 值类型 | 说明 |
|---|---|---|---|
| MultiLineText | 文本 | string | |
| Date | 日期 | string | |
| Time | 时间 | string | |
| Number | 数值 | numeric | |
| Currency | 货币 | numeric | |
| Percentage | 百分比 | numeric | |
| ID | 身份证 | string | |
| Phone | 电话 | string | |
| 电子邮箱 | string | ||
| Url | 超链接 | object | 不支持通过 Python 更新 |
| Checkbox | 复选框 | boolean | |
| SingleSelect | 单选项 | object | 不支持通过 Python 更新 |
| MultipleSelect | 多选项 | object | 不支持通过 Python 更新 |
| Rating | 等级 | numeric | 会被降级成 Number 类型 |
| Complete | 进度条 | numeric | |
| Contact | 联系人 | object | 不支持通过 Python 更新 |
| Attachment | 附件 | object | 不支持通过 Python 更新 |
| Link | 关联 | object | 不支持通过 Python 更新 |
| Note | 富文本 | object | 不支持通过 Python 更新 |
| Address | 地址 | object | 不支持通过 Python 更新 |
| Cascade | 级联 | object | 不支持通过 Python 更新 |
以下类型为数据表中的自动类型,即该类型的记录值是系统自动填充的,不支持外部更新。
| 字段类型 | 类型名称 |
|---|---|
| AutoNumber | 编号 |
| CreatedBy | 创建者 |
| CreatedTime | 创建时间 |
| LastModifiedBy | 最后修改者 |
| LastModifiedTime | 最后修改时间 |
| Formula | 公式 |
| Lookup | 引用 |
dbt() 函数
函数签名
python
def dbt(field: str | list[str] = None,
sheet_name: str | list[str] = '',
book_url: str = '') -> __pd.DataFrame | dict[str, __pd.DataFrame]:参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| field | str or list | None | 要返回的字段列表。 默认为 None,表示返回所有字段。 |
| sheet_name | str or list | 空字符串 | 字段所在的数据表名称,可为多个。 默认为当前激活的数据表。 如果为 None则返回全部数据表数据。 |
| book_url | str | 空字符串 | 字段所在的表格文件地址。 必须为金山文档云文档地址。 默认当前表格。 |
注意
dbt() 函数返回的 pandas.DataFrame.index 中包含每一条记录的 ID,供更新数据表使用时使用。
示例
以下示例会使用到如下虚拟的进销存表格,并假设当前正在打开的是数据表1(激活状态)。
提示
表格中的数据均虚构,仅做示例使用。
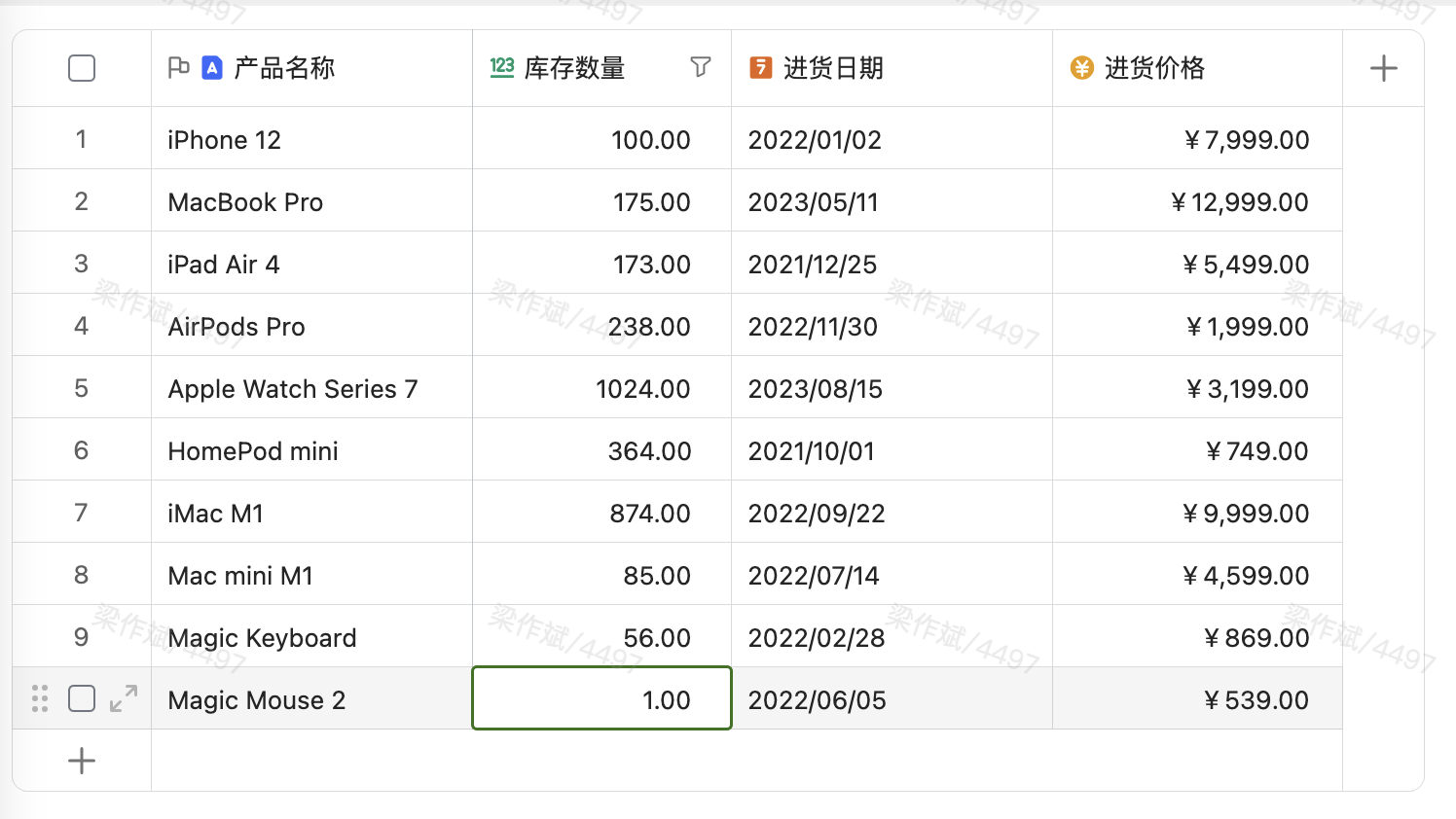
- 读取当前数据表(数据表1)中的产品名称和库存数量。
python
# 返回数据表1中的字段名为产品名称和库存数量的记录,表头为字段名
# 返回的数据类似下表所示
# 其中 B,C,D 为 Index 中保存的记录 ID
# +-----+-------------+----------+
# | | 产品名称 | 库存数量 |
# +-----+-------------+----------+
# | B | iPhone 12 | 100 |
# +-----+-------------+----------+
# | C | MacBook Pro | 175 |
# +-----+-------------+----------+
# | D | iPad Air 4 | 173 |
# +-----+-------------+----------+
df = dbt(field=['产品名称', '库存数量'])- 读取当前数据表中,数据表1和数据表2的所有记录
python
# 此时返回的是一个包括两个 DataFrame 的 dict
ds = dbt(sheet_name=['数据表1', '数据表2'])
df1 = ds['数据表1']
df2 = ds['数据表2']- 读取其它文档(
https://www.kdocs.cn/l/bar)中的全部数据表中记录
python
# 此时返回的是一个包括多个 DataFrame 的 dict
ds = dbt(sheet_name=None, book_url="https://www.kdocs.cn/l/bar")insert_dbt() 函数
函数签名
python
def insert_dbt(data: dict[str, any] | list[dict[str, any]] | __pd.DataFrame,
sheet_name: str = '',
new_sheet: bool = False) -> None:参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| data | object | 必填 | 要回写到数据表里的数据。 支持的数据类型包括: dict[str, any]包含记录名称和值的 dict;维度不超过2维的 list 类型;pandas.DataFrame;不支持写入附件等复杂类型。 |
| sheet_name | str | 空字符串 | 写入数据的选区所在的数据表名称。 当 new_sheet=False 时为表格中已经存在的数据表名称。当 new_sheet=True 时为新建的数据表的名称。 |
| new_sheet | bool | False | 是否将数据写入到新建的数据表中。 |
提示
建议直接使用 dbt() 函数返回的 DataFrame,进行所需要的处理后,回写数据表。
示例
python
# 返回数据表1中的字段名为产品名称和库存数量的记录,表头为字段名
# 返回的数据类似下表所示
# 其中 B,C,D 为 Index 中保存的记录 ID
# +-----+-------------+----------+
# | | 产品名称 | 库存数量 |
# +-----+-------------+----------+
# | B | iPhone 12 | 100 |
# +-----+-------------+----------+
# | C | MacBook Pro | 175 |
# +-----+-------------+----------+
# | D | iPad Air 4 | 173 |
# +-----+-------------+----------+
df = dbt(field=['产品名称', '库存数量'])
# 将 df 中的数据写入到新的数据表2中
insert_dbt(df, sheet_name="数据表2", new_sheet=True)
# 向数据表2中,新增一条记录
insert_dbt({"产品名称": "iPad Air 5", "库存数量": 100 }, sheet_name="数据表2")
# 向数据表2中,新增两条记录
insert_dbt([{"产品名称": "Mac mini M2"}, {"产品名称": "Mac mini M2 Pro"}] , sheet_name="数据表2")update_dbt() 函数
函数签名
python
def update_dbt(data: dict[str, any] | list[dict[str, any]] | __pd.DataFrame,
sheet_name: str = '') -> None:参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| data | object | 必填 | 要回写到数据表里的数据。 支持的数据类型包括: dict[str, any]包含记录ID、名称和值的 dict;维度不超过2维的 list 类型;pandas.DataFrame;不支持写入附件等复杂类型。 |
| sheet_name | str | 空字符串 | 写入数据的选区所在的数据表名称。 当 new_sheet=False 时为表格中已经存在的数据表名称。当 new_sheet=True 时为新建的数据表的名称。 |
| new_sheet | bool | False | 是否将数据写入到新建的数据表中。 |
示例
python
# 返回数据表1中的字段名为产品名称和库存数量的记录,表头为字段名
# 返回的数据类似下表所示
# 其中 B,C,D 为 Index 中保存的记录 ID
# +-----+-------------+----------+
# | | 产品名称 | 库存数量 |
# +-----+-------------+----------+
# | B | iPhone 12 | 100 |
# +-----+-------------+----------+
# | C | MacBook Pro | 175 |
# +-----+-------------+----------+
# | D | iPad Air 4 | 173 |
# +-----+-------------+----------+
df = dbt(field=['产品名称', '库存数量'])
# 修改 df 中的数据,并更新数据表中的记录
df['库存数量'] = df['库存数量'] * 2
update_dbt(df)
# 单独修改数据表1中的记录
# 其中包括ID字段 _rid 值为对应的 Index 中的值
update_dbt({"_rid": "B", "产品名称": "iPhone 12 Pro"})
# 更新多条记录的值
update_dbt([{"_rid": "C", "产品名称": "MacBook Pro M1"}, {"_rid": "D", "库存数量": 200}])echarts() 函数
函数签名
python
def echarts(options: dict) -> pyecharts.charts.base.Base参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| options | dict | 必填 | echarts 配置,可以直接从echarts官方示例中拷贝配置并执行查看显示效果 |
示例
python
options = {
"xAxis": {
"type": "category",
"data": ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
},
"yAxis": {"type": "value"},
"series": [{
"type": "line",
"data": [150, 230, 224, 218, 135, 147, 260]
}]
}
echarts(options).render()内置的第三方依赖
按字母顺序排序 | 简介 |
|---|---|
| akshare | AkShare是基于Python的开源金融数据接口库,目的是实现对股票、期货、期权、基金、债券、外汇等金融产品和另类数据从数据采集,数据清洗到数据下载的工具,满足金融数据科学 |
| astropy | Astropy用于天文学数据处理和分析。它提供了许多有用的工具和函数来操作各种类型的天文学数据,从图像和表格到天体物理学常见的坐标系转换和单位转换 |
| baostock | BaoStock是一个证券数据服务平台。考虑到 Python pandas 包在金融量化分析中体现出的优势, BaoStock 返回的绝大部分的数据格式都是 pandas DataFrame 类型,非常便于用 pandas/NumPy/Matplotlib 进行数据分析和可视化 |
| bs4 | Beautiful Soup(简称BS4)是一个用于解析HTML和XML文档的Python库。它提供了一种简单而灵活的方式来导航、搜索和修改解析树,使得从网页中提取数据变得更加容易 |
| Cartopy | Cartopy是一个Python包,用于地理空间数据处理,以便生成地图和其他地理空间数据分析。 Cartopy利用了强大的PROJ.4、NumPy和Shapely库,并在Matplotlib之上构建了一个编程接口,用于创建发布高质量的地图 |
| imbalanced-learn | imbalanced-learn提供了一些技术来解决数据不平衡的问题。在分类问题中,如果数据集中的一个类别的样本数量远远大于另一个类别,这会导致模型对多数类别的偏向,从而降低对少数类别的识别能力。这种情况下,imbalanced-learn库可以帮助提高模型对少数类别的识别能力 |
| IPython | IPython是一个交互式计算环境的扩展库,提供了一个强大的交互式环境和工具集,提供了许多方便的功能和特性,使得开发者可以更加高效地编写、测试和调试Python代码。它是Python数据科学和机器学习领域中常用的工具之一 |
| matplotlib | Matplotlib是Python中一个常用的绘图库,可以用于绘制各种类型的图表,包括线图、散点图、条形图、等高线图、3D图等等。它是一个非常强大和灵活的库,被广泛用于数据科学、机器学习、工程学、金融等领域 |
| networkx | NetworkX是一个用于创建、操作和学习复杂网络的Python库。它提供了一组丰富的工具和算法,用于分析和可视化网络结构,以及研究网络的属性和行为 |
| nltk | Natural Language Toolkit(简称NLTK)是一个用于自然语言处理(NLP)的Python库。它提供了一系列工具和数据集,用于处理、分析和理解文本数据 |
| numpy | NumPy(Numerical Python)是一个用于科学计算的Python库。它提供了一个高性能的多维数组对象(ndarray)和一组用于操作数组的函数,使得在Python中进行数值计算和数据处理变得更加高效和方便 |
| pandas | Pandas是一个开源的数据分析和数据处理库,它是基于NumPy构建的,提供了高性能、易于使用的数据结构和数据分析工具,使得在Python中进行数据处理和分析变得更加简单和高效 |
| pyecharts | Pyecharts是一个用于生成交互式图表和可视化的Python库,它基于Echarts JavaScript库,并提供了一种简单而强大的方式来创建各种类型的图表。通过Pyecharts,可以轻松地将数据转化为各种图表,如折线图、柱状图、散点图、饼图等等,并且可以对图表进行各种定制,如修改颜色、添加标签、调整字体等等。使用Pyecharts可以大大提高数据可视化的效率,让用户更加直观地了解数据的分布和规律。同时,Pyecharts也支持多种输出格式,如HTML、PDF等,方便用户将图表嵌入到Web页面或生成报告中使用 |
| pymysql | PyMySQL是Python中用于连接和操作MySQL数据库的一个库。它提供了Python编程语言和MySQL数据库之间的接口,使得Python程序可以方便地连接、查询和操作MySQL数据库 |
| pytorch | PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。PyTorch的易用性使得它在研究社区中有了早期的使用者,并且已经成为应用程序中使用最广泛的深度学习工具之一 |
| pywavelets | PyWavelets是Python中用于小波变换的免费开源库。小波是在时间和频率上都局部化的数学基函数,小波变换则是利用小波的时频变换来分析和处理信号或数据。PyWavelets提供了丰富的功能和灵活的接口,可以对图像、音频、信号等数据进行小波变换、逆变换、阈值去噪、压缩等操作。此外,PyWavelets还支持多种小波基函数和边界处理方式,用户可以根据需要选择合适的小波基函数和参数 |
| requests | requests库是Python的一个HTTP客户端库,可以帮助用户发送各种类型的HTTP请求,如GET、POST、PUT、DELETE等,并获取响应。requests库具有简单易用、功能强大、灵活性高等特点,因此被广泛应用于Python网络编程中 |
| scikit-image | Scikit-image是一个基于Python脚本语言开发的数字图片处理包,它将图片作为numpy数组进行处理,正好与matlab一样。scikit-image对scipy.ndimage进行了扩展,提供了更多的图片处理功能。Scikit-image库包含了一些基本的图像处理功能,比如图像缩放、旋转、图像变换、阈值化处理等等。此外,它还包含了众多高级图像处理算法,比如边缘检测、形态学操作、直线和圆检测等等 |
| scikit-learn | Scikit-learn(以前称为scikits.learn,也称为sklearn)是一个简单高效的数据挖掘和数据分析工具,建立在Python编程语言之上。它是为了解决真实世界中的问题而开发的,并且在学术和商业环境中都得到了广泛的应用。Scikit-learn的主要功能包括分类、回归、聚类、降维、模型选择和预处理 |
| scipy | scipy是一个基于Python的开源科学计算库,它建立在NumPy库的基础上,提供了更高级的数学、科学和工程计算功能。scipy库包含了许多模块,每个模块都提供了一组相关的函数和工具,用于解决各种数学、科学和工程问题 |
| seaborn | Seaborn是一个基于Python的数据可视化库,它在matplotlib的基础上进行了更高级的API封装,使得作图更加容易,并且制作出来的图形也更加美观和具有吸引力。Seaborn提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表 |
| statsmodels | statsmodels是一个Python库,提供了用于统计建模和计量经济学的函数和类。它包含了一系列统计模型,用于数据分析、探索性数据分析(EDA)、建模和推断。该库的目标是提供一种简单而一致的接口,使得用户可以在Python中进行各种统计任务 |
| sympy | sympy是一个基于Python的符号计算库,它提供了符号计算的功能,可以进行符号代数、微积分、线性代数、离散数学等方面的计算。与其他数值计算库不同,sympy库执行的是精确计算,而不是数值近似,这使得它非常适合用于数学推导、符号计算和数学建模 |
| tushare | tushare是一个基于Python的金融数据接口库,它提供了丰富的金融市场数据,包括股票、指数、基金、期货、外汇等数据。tushare库获取数据的来源是中国的金融市场,可以帮助获取和分析金融数据 |