 Python文档
Python文档主题
dbt() 函数
使用dbt()函数读取数据表中的数据。
函数签名
python
def dbt(field: str | list[str] = None,
sheet_name: str | list[str] = '',
book_url: str = '') -> __pd.DataFrame | dict[str, __pd.DataFrame]:
参数列表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| field | str or list | None | 要返回的字段列表。 默认为 None,表示返回所有字段。 |
| sheet_name | str or list | 空字符串 | 字段所在的数据表名称,可为多个。 默认为当前激活的数据表。 如果为 None则返回全部数据表数据。 |
| book_url | str | 空字符串 | 字段所在的表格文件地址。 必须为金山文档云文档地址。 默认当前表格。 |
注意
dbt() 函数返回的 pandas.DataFrame.index 中包含每一条记录的 ID,供更新数据表使用时使用。
示例
以下示例会使用到如下虚拟的进销存表格,并假设当前正在打开的是数据表1(激活状态)。
提示
表格中的数据均虚构,仅做示例使用。
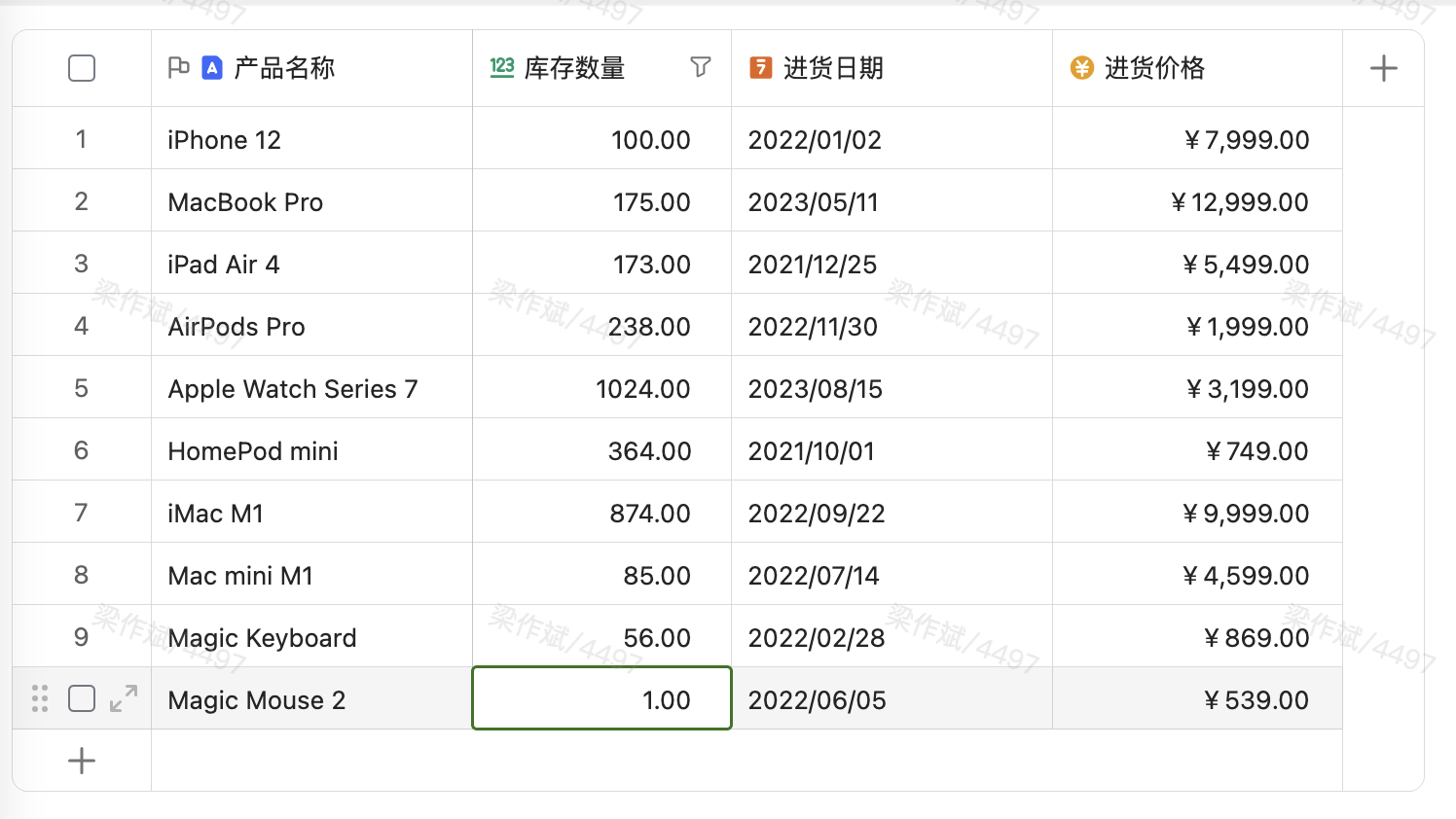
- 读取当前数据表(数据表1)中的产品名称和库存数量。
python
# 返回数据表1中的字段名为产品名称和库存数量的记录,表头为字段名
# 返回的数据类似下表所示
# 其中 B,C,D 为 Index 中保存的记录 ID
# +-----+-------------+----------+
# | | 产品名称 | 库存数量 |
# +-----+-------------+----------+
# | B | iPhone 12 | 100 |
# +-----+-------------+----------+
# | C | MacBook Pro | 175 |
# +-----+-------------+----------+
# | D | iPad Air 4 | 173 |
# +-----+-------------+----------+
df = dbt(field=['产品名称', '库存数量'])
- 读取当前数据表中,数据表1和数据表2的所有记录
python
# 此时返回的是一个包括两个 DataFrame 的 dict
ds = dbt(sheet_name=['数据表1', '数据表2'])
df1 = ds['数据表1']
df2 = ds['数据表2']
- 读取其它文档(
https://www.kdocs.cn/l/bar)中的全部数据表中记录
python
# 此时返回的是一个包括多个 DataFrame 的 dict
ds = dbt(sheet_name=None, book_url="https://www.kdocs.cn/l/bar")